by Lars Kamp
How you can access your “dark data” with Amazon Redshift Spectrum
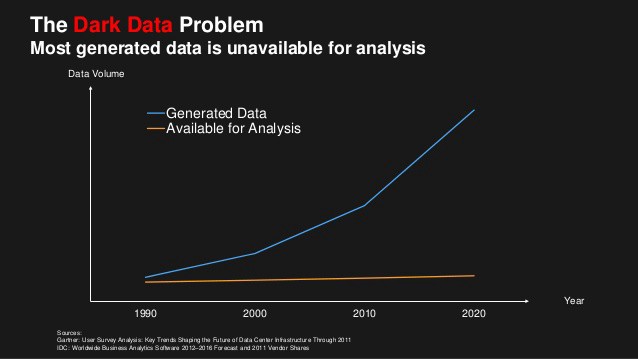
Amazon’s Simple Storage Service (S3) has been around since 2006. Enterprises have been pumping their data into this data lake at a furious rate. Within 10 years of its birth, S3 stored over 2 trillion objects, each up to 5 terabytes in size. These companies know their data is valuable and worth preserving. But much of this data lies inert, in “cold” data lakes, unavailable for analysis, as so-called “dark data.”
Analyzing “Dark Data”
So what lies below the surface of data lakes? The first thing for organizations to do is to find out what dark data they have accumulated. Then then need to analyze it in search of valuable insights. That means analysts need solutions that allow them to access petabytes of dark data.
With Amazon Redshift Spectrum, you can query data in Amazon S3 without first loading it into Amazon Redshift. For nomenclature purposes, I’ll use “Redshift” for “Amazon Redshift,” and “Spectrum” for “Amazon Redshift Spectrum.”
There are three major existing ways to access and analyze data in S3.
- Amazon Elastic MapReduce (EMR). EMR uses Hadoop-style queries to access and process large data sets in S3.
- Amazon Athena. Athena offers a console to query S3 data with standard SQL and no infrastructure to manage. Athena also has an API.
- Amazon Redshift. You can load data from S3 into an Amazon Redshift cluster for analysis.
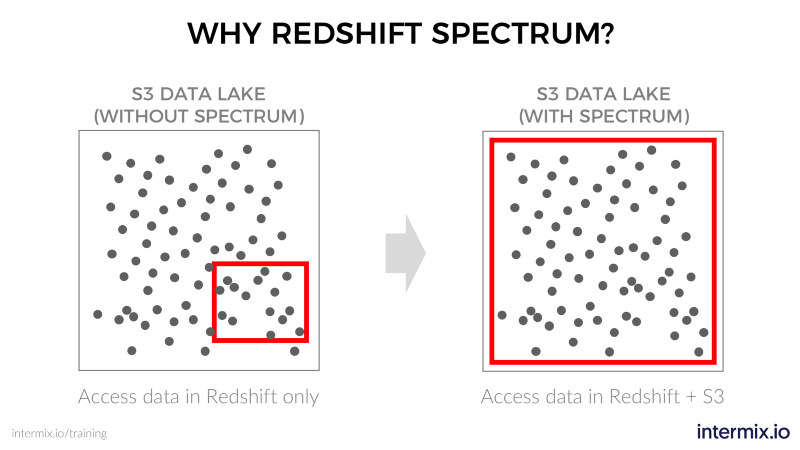
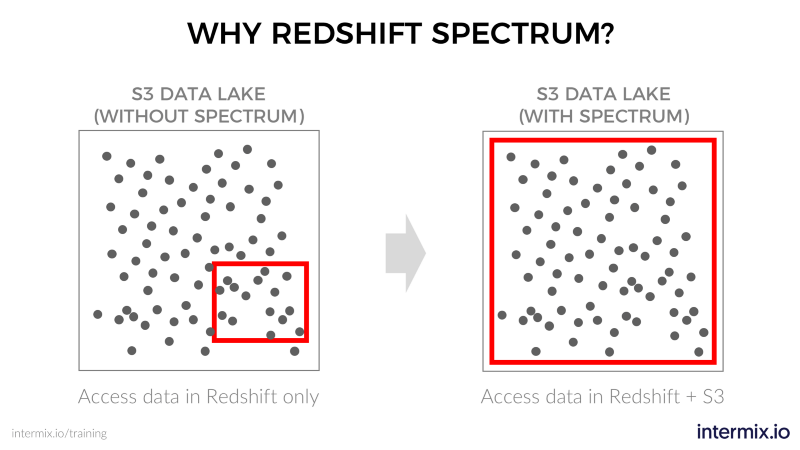
So why not use these existing options? For example, companies already use Amazon Redshift to analyze their “hot” data. So why not load that cold data from S3 into Redshift and call it a day?
There are two main reasons:
- Effort. Loading data into Amazon Redshift involves extract, transform, and load (ETL) steps. Those steps are necessary to convert and structure data for analysis. Amazon estimates that figuring out the right ETL consumes 70% of an analytics project.
- Cost. You may not even know what data to extract until you have analyzed it a bit. Uploading lots of cold S3 data for analysis requires growing your clusters. That translates to paying more, as Redshift pricing is based on the size of your cluster. Meanwhile, you continue to pay S3 storage charges for retaining your cold data.
Redshift Spectrum offers the best of both worlds. With Spectrum, you can:
- Continue using your analytics applications, with the same queries you’ve written for Redshift.
- Leave cold data as-is in S3, and query it via Amazon Redshift, without ETL processing. That includes joining data from your data lake with data in Redshift, using a single query.
- Decouple processing from storage. Because there’s no need to increase cluster size, you can save on Redshift storage.
- Pay only when you run queries against S3 data. Spectrum queries cost a reasonable $5 /terabyte of data processed.
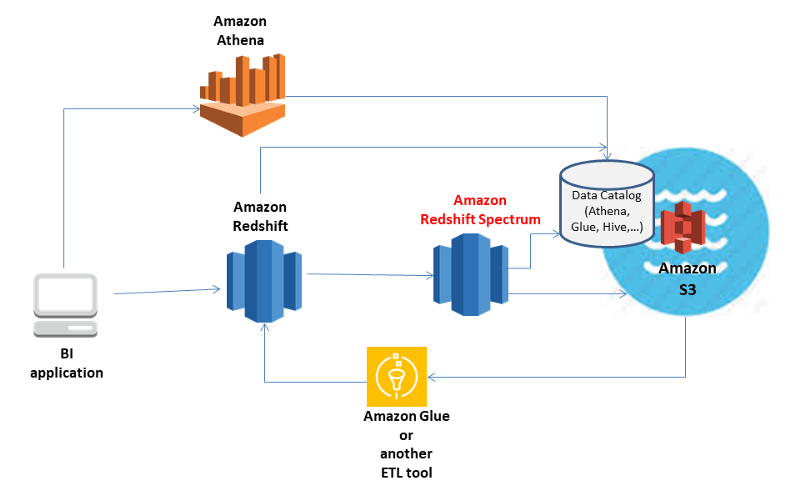
Spectrum is the “glue” or “bridge” layer that provides Redshift an interface to S3 data. Redshift becomes the access layer for your business applications. Spectrum is the query processing layer for data accessed from S3. The above picture illustrates the relationship between these services.
A closer look at Redshift Spectrum
From a deployment perspective, Spectrum is “under the hood.” It’s a group of managed nodes in your VPC, available to any of your Redshift clusters that are Spectrum-enabled. It pushes compute-intensive tasks down to the Redshift Spectrum layer. That layer is independent of your Amazon Redshift cluster.
There are three key concepts to understand how to run queries with Redshift Spectrum:
- External data catalog
- External schemas
- External tables
The external data catalog contains the schema definitions for the data you wish to access in S3. It’s a central metadata repository for your data assets.
The external schema contains your tables. External tables allow you to query data in S3 using the same SELECT syntax as with other Amazon Redshift tables. External tables are read-only, that is, you can’t write to an external table.
You can keep writing your usual Redshift queries. The main change with Spectrum is that the queries now also contain a reference to data stored in S3.
Joining internal and external tables
The Redshift query engine treats internal and external tables the same way. You can do the typical operations like queries and joins on either type of table or a combination of both. Query an external table and join its data with that from an internal one.
As an example, let’s say you are using Redshift to analyze data of your e-commerce site visitors. What pages they visit, how long they stay, what they buy (or not), and so on. You keep a year’s worth of data in your Redshift clusters. Older data you move to S3.
Then you notice an odd seasonal variation. You want to see if this was also true for past years, or if it was an aberration for this year. Luckily you have saved historic clickstream data in S3, going back many years. You can now access that historic data via an external table with Spectrum, and run the same queries you’re running in Amazon Redshift. Or you can create new insights by joining other past data with this year’s data.
Redshift parses, compiles, and distributes an SQL query to the nodes in a cluster the normal way. The part of the query that references an external data source gets sent to Spectrum. Spectrum processes the relevant data in S3, and sends the result back to Redshift. Redshift collects the partial results from its nodes and Spectrum, concatenates and joins them (and so on), and returns the complete result.
Summary
Here are a few points to keep in mind when working with Spectrum:
- Your business applications remain unchanged and don’t know how or where a query is running. The only change for the business analyst is when defining access to external tables.
- External data remains in S3 — there is no ETL to load it into your Redshift cluster. That decouples your storage layer in S3 from your processing layer with Redshift and Spectrum.
- You don’t need to increase the size of your Redshift cluster to process data in S3. You only pay for the S3 data your queries actually access.
- Redshift does all the hard work of minimizing the number of Spectrum nodes needed to access the S3 data. It also makes processing between Redshift and Spectrum efficient.
You should also do the homework to ensure that processing of data in S3 is economical and efficient. You can save on costs and get better performance if you partition the data, compress it, or convert it to columnar formats such as Apache Parquet.
In summary, Spectrum adds one more tool to your Redshift-based data warehouse investment. You can now use its power to probe and analyze your data lake on an as-needed basis for a very low per query price.
I’m the cofounder of intermix.io. If you want to check it out, you can do so here.
Originally published at www.intermix.io.