by Prithviraj Pawar
How to get your GraphQL Java server up and running in no time
GraphQL is a query language for fetching data over the internet. Since its public announcement by Facebook in 2015, it has sparked interest in many minds. GraphQL has primarily been used in JavaScript. In fact, Facebook released the reference implementation for it in JavaScript (graphql-js).
But this blog post will focus on the development of the GraphQL server in Java. GraphQL-Java is the corresponding GraphQL implementation in Java, and it gets updates and version improvements almost every month. Features like instrumentation, asynchronous calls to the backend, the dataloader, directives, and many more make it a very interesting and powerful repository in Java.

How to build a GraphQL Java Server in springboot
Let’s take the example of a magic school from the Harry Potter Universe. The magic school’s data is as follows:
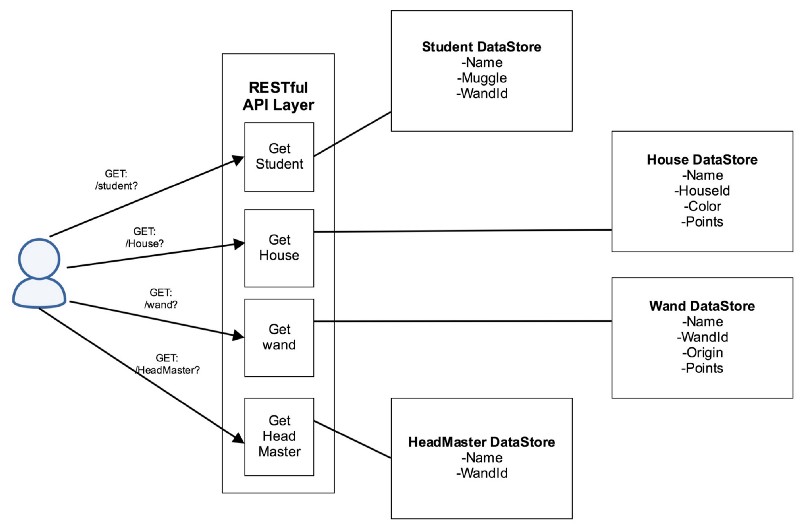
Here the DataStores can be backend servers, or even Databases. A RESTful fetching will look like below.
GET: /student?{parameters}GET: /House?{parameters}Basically expose an interface for a service. Thus if Professors are added in the above model, then a new endpoint has to be opened and the client has to take multiple round trips. Also if the client wants nested data like Harry’s wand origin or Ron’s house color, then the API server has to call the backend twice. It will also result in some unwanted House and wand information.
Enter GraphQL: GraphQL is a schema-driven approach to fetching data. It models the data as graphs, and you have to issue a query to fetch the data. It works like SQL, but for web objects. So, a graphQL query for Harry looks like:
query{Magic School{Student{namewand{origin}}}}Before going into GraphQL, we need to setup a spring MVC. The easiest way to do this is SpringBootStarter. You can select your desired build automation tool . This gives a package of spring embedded Tomcat ready to run on port 8080. To test Tomcat, run:
$gradle clean build$java -jar ./build/libs/graphql-demo-0.0.1-SNAPSHOT.jarBy default, Gradle names your JAR “project_name-version-SNAPSHOT.jar”. Check http:localhost:8080 to see Tomcat running on port 8080.
Let’s now add a GraphQL-Java dependency in our build.gradle.
dependencies {compile('com.graphql-java:graphql-java:{version}')compile group: 'org.json', name: 'json', version: '20170516'}Add the current version as found in the mavenCentral repository. Currently, the latest version is 8.0. Also add org.json, which is a handy library as GraphQL handles the request-response in JSON.
As I mentioned earlier, GraphQL is a schema-driven language. It asks users to select objects in the query against the schema.
Let’s dive right in:
We have opened a /graphql interface for GraphQL POST requests. We need to create a schema for representing data.
- SchemaGenerator parses the schema and creates an Abstract Syntax Tree with field names as the child nodes.
- Then the fields are assigned types by TypeDefinitionRegistry, for example Int, String, and so on. GraphQL has a nice Type system wherein we can have custom types in the schema including enum, interfaces, unions, Lists, and more.
- Take a look at the RuntimeWiring() step where the field “MagicSchool” is mapped to “Hogwarts” by a StaticDataFetcher.
- Every field is backed up by a datafetcher, and it is the job of datafetcher to resolve the data and return to GraphQL.
- Then GraphQL wires it with the defined schema names, whether it’s a nested map of lists or a generic Map. GraphQL does it as long as you define the proper schema.
- After Sending this data to ExecutionInput, the GraphQL engine parses-> validates->fetches->executes the query and returns you a JSON output of the response using .toSpecifiation()
Let’s issue a query using GraphiQL. Add this extension to your browser and set the endpoint.
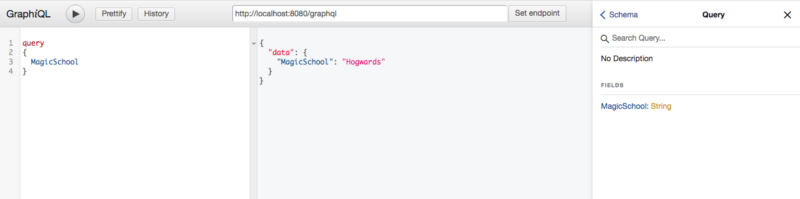
Look how the shape of your query determines the shape of the response. The schema can be visualized neatly because of the introspective nature of GraphQL. This enables the Validation and Syntax checking of the schema automatically due to the Abstract Syntax Tree created while parsing the schema.
Let’s add some more fields in the schema. We’ll build a Schema Definition Language. Create a file named magicSchool.graphql.
type Query{magicSchool:MagicSchool}type MagicSchool{name: StringHeadMaster:Stringstudent:Student}type Student{name:Stringwand:Wandhouse:House}type House{name:Stringcolor:Stringpoints:Int}type Wand{name:Stringorigin:String}Modify the schema source in the code and check the new schema in GraphiQL
File schemaFile = loadSchema("magicSchool.graphql");TypeDefinitionRegistry typeRegistry=schemaParser.parse(schemaFile);The runtimeWiring for the schema and fetchers changes significantly to include the other Types. Each type has its independent DataFetcher.
Here we have @Autowired all the fetchers to get us the data. Every GraphQL type is backed up by a type resolver (data fetcher). These resolvers are independent of each other and can have different sources. Every DataFetcher here has a DatafetchingEnvironment, which is an interface into the GraphQL query execution. It contains the query-arguments, context, executionId, field-specific parameters, and so on.
Take a look at StudentFetcher and the Output of our query (ignore the Extensions):
public DataFetcher getData() { return environment -> { Map<String, Object> student = new HashMap<>(); if ("1".equalsIgnoreCase(environment.getArgument("id"))) { student.put("name", "Harry Potter"); } return student; };}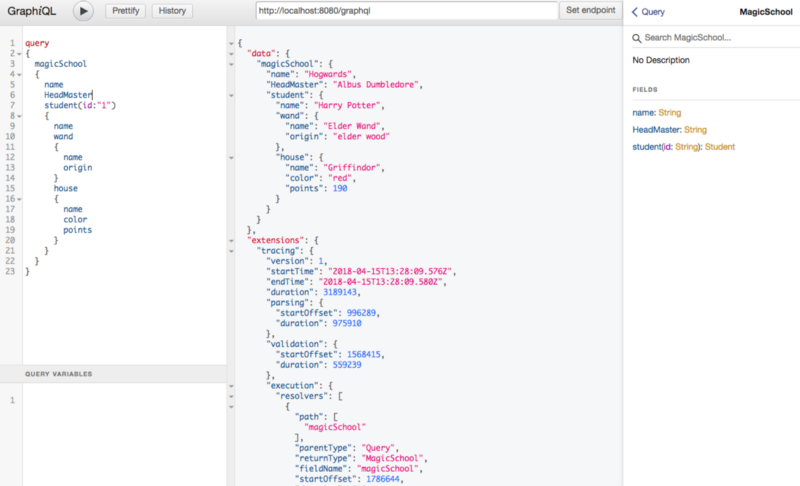
Reminds you of SQL, doesn’t it? Also see how Underfetching and Overfetching get eliminated, and the control of the data is all in the client’s hands. Now we can get Harry and Ron’s information neatly and in one call to the server!
GraphQL Execution Strategy and Instrumentation
Each query execution is Asynchronous in graphql-java. When you call build.execute(executionInput), it returns a CompletableFuture object which gets completed when the query completes its flow of execution.
Also, as the fields are resolved separately, in the above example the Wand and House information are fetched and executed in parallel. The default ExecutionStrategy uses Java’s fork-join pool, but you can add your custom threadpool using the Executor Class.
ExecutorService executorService = new ThreadPoolExecutor( 128, /* core pool size 128 threads */ 256, /* max pool size 256 threads */ 10, TimeUnit.SECONDS, new LinkedBlockingQueue<Runnable>(), new ThreadPoolExecutor.CallerRunsPolicy()); return GraphQL.newGraphQL() .instrumentation(new TracingInstrumentation ()) .queryExecutionStrategy(new ExecutorServiceExecutionStrategy(executorService)) .build();}graphql-java allows you to instrument the query execution at every point: beforeExecution, beforeParsing, and beforeFetching. You can extend the Instrumentation class and provide your own action at each step — for example, logging the queries and returning the time of each step.
The instrumentation output provides an extensions map in Apollo Tracing format by default. This can later be used by a certain client to visualize the execution data (for example, using elastic-search and Grafana). Now you know what the extensions in the above picture mean!
The complete code of the above example can be accessed from here.
Wrapping up
There are many more features in graphql-java, like Dataloader (which solves the N+1 fetching problem), directives (which make schema writing easier), and so on. GraphQL is an emerging technology that makes the client’s life easier and can change how we do things on the Internet. That is why many companies like Facebook, Twitter, GitHub, and Coursera have already adopted it.
I would love to hear your comments about GraphQL. Please share your views. Also if you like the blog post, don’t forget to clap.