by Yan Cui
How to auto-create CloudWatch Alarms for APIs with CloudWatch Events and Lambda
In a previous post, I discussed how to auto-subscribe a CloudWatch Log Group to a Lambda function using CloudWatch Events. The benefit of this is that we don’t need a manual process to ensure all Lambda logs are forwarded to our log aggregation service.
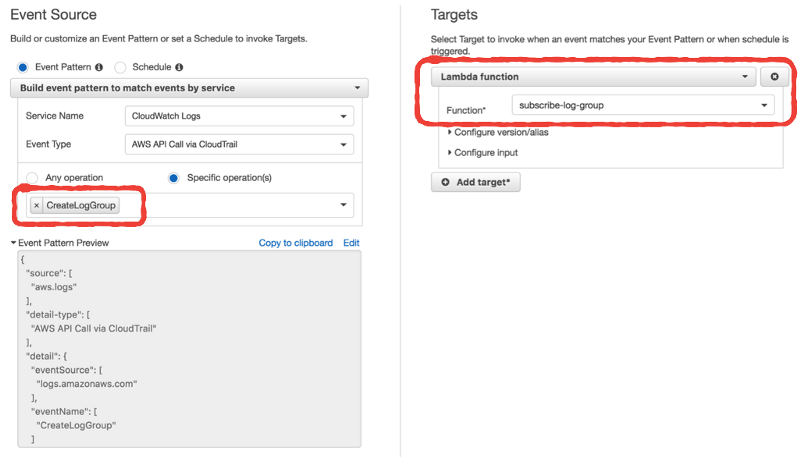
Whilst this is useful in its own right, it only scratches the surface of what we can do. CloudTrail and CloudWatch Events make it easy to automate many day-to-day operational steps, with the help of Lambda of course ?
I work with API Gateway and Lambda a lot. Whenever you create a new API, or make changes, there are several things you need to do:
- Enable Detailed Metrics for the deployment stage
- Set up a dashboard in CloudWatch, showing request count, latencies, and error counts
- Set up CloudWatch Alarms for P99 latencies and error counts
Because these are manual steps, they often get missed.
Have you ever forgotten to update the dashboard after adding a new endpoint to your API? And did you also remember to set up a P99 latency alarm on this new endpoint? How about alarms on the number of 4XX or 5xx errors?
Most teams I’ve dealt with have some conventions around these, but they don’t have a way to enforce them. The result is that the convention is applied in patches and cannot be relied upon. I find that this approach doesn’t scale with the size of the team.
It works when you’re a small team. Everyone has a shared understanding, and the necessary discipline to follow the convention. When the team gets bigger, you need automation to help enforce these conventions.
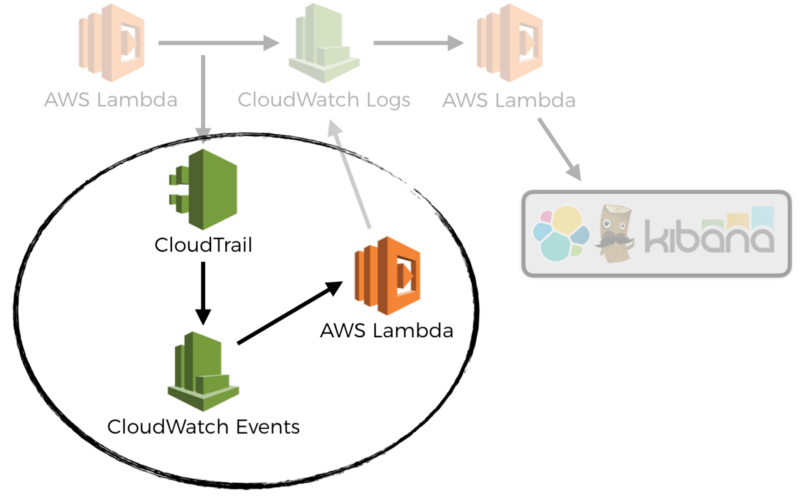
Fortunately, we can automate away these manual steps using the same pattern. In the Monitoring unit of my course Production-Ready Serverless, I demonstrated how you can do this in 3 simple steps:
- CloudTrail captures the CreateDeployment request to API Gateway
- CloudWatch Events pattern against this captured request
- Lambda function to enable detailed metrics, and create alarms for each endpoint
If you use the Serverless framework, then you might have a function that looks like this:
A couple of things to note from the code above:
- I’m using the serverless-iam-roles-per-function plugin to give the function a tailored IAM role
- The function needs the
apigateway:PATCHpermission to enable detailed metrics - The function needs the
apigateway:GETpermission to get the API name and REST endpoints - The function needs the
cloudwatch:PutMetricAlarmpermission to create the alarms - The environment variables specify SNS topics for the CloudWatch Alarms
The captured event looks like this:
We can find the restApiId and stageName inside the detail.requestParameters attribute. That’s all we need to figure out what endpoints are there, and so what alarms we need to create.
Inside the handler function, which you can find here, we perform a few steps:
- Enable detailed metrics with an
updateStagecall to API Gateway - Get the list of REST endpoints with a
getResourcescall to API Gateway - Get the REST API name with a
getRestApicall to API Gateway - For each of the REST endpoints, create a P99 latency alarm in the
AWS/ApiGatewaynamespace
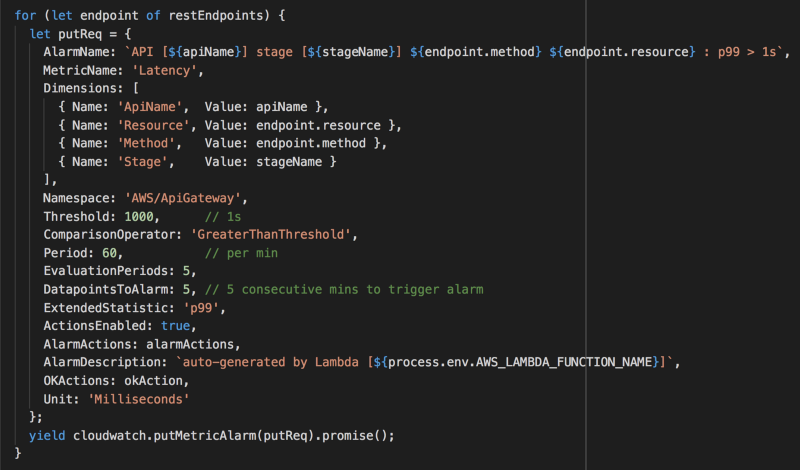
Now, every time I create a new API, I will have CloudWatch Alarms to alert me when the 99 percentile latency for an endpoint goes over 1 second, for 5 minutes in a row.
All this, with just a few lines of code ?
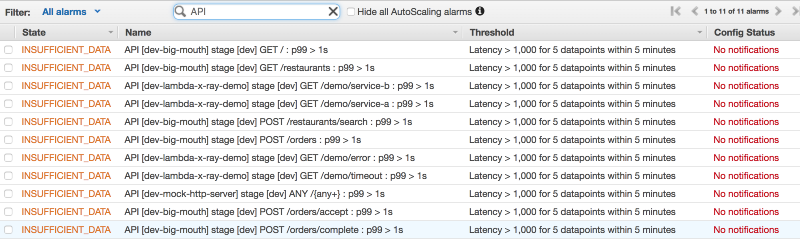
You can take this further, and have other Lambda functions to:
- Create CloudWatch Alarms for 5xx errors for each endpoint
- Create CloudWatch Dashboard for the API
So there you have it! A useful pattern for automating away manual operational tasks.
And before you tell me about the ACloudGuru AWS Alerts Serverless plugin by the ACloudGuru folks, yes I’m aware of it. It looks neat, but it’s ultimately still something the developer has to remember to do.
That requires discipline.
My experience tells me that you cannot rely on discipline, ever. Which is why I prefer to have a platform in place that will generate these alarms instead.