by Andrea Santurbano
How to produce and consume Kafka data streams directly via Cypher with Streams Procedures
Leveraging Neo4j Streams — Part 3
This article is the third part of the Leveraging Neo4j Streams series (Part 1 is here, Part 2 is here). In it, I’ll show you how to bring Neo4j into your Apache Kafka flow by using the streams procedures available with Neo4j Streams.
In order to show how to integrate them, simplify the integration, and let you test the whole project by hand, I’ll use Apache Zeppelin, a notebook runner that simply allows you to natively interact with Neo4j.
What is a Neo4j Stored Procedure?
Starting from Neo4j 3.x, the concept of user-defined procedures and functions was introduced. These are custom implementations of certain functionalities and/or business rules that can’t be (easily) expressed in Cypher itself.
Neo4j provides a number of built-in procedures. The APOC library adds another 450 to cover all kinds of uses from data integration to graph refactorings.
What are the streams procedures?
The Neo4j Streams project comes out with two procedures:
streams.publish: allows custom message streaming from Neo4j to the configured environment by using the underlying configured Producerstreams.consume: allows consuming messages from a given topic.
Set-Up the Environment
Going to the following Github repo, you’ll find everything necessary in order to replicate what I’m presenting in this article. What you will need to start is Docker, and then you can simply spin-up the stack by entering into the directory and from the Terminal execute the following command:
$ docker-compose upThis will start-up the whole environment that comprises:
- Neo4j + Neo4j Streams module + APOC procedures
- Apache Kafka
- Apache Spark (which is not necessary in this article, but it’s used in the previous two)
- Apache Zeppelin
By going into Apache Zeppelin @ http://localhost:8080 you’ll find in directory Medium/Part 3 one notebook called “Streams Procedures” which is the subject of this article.
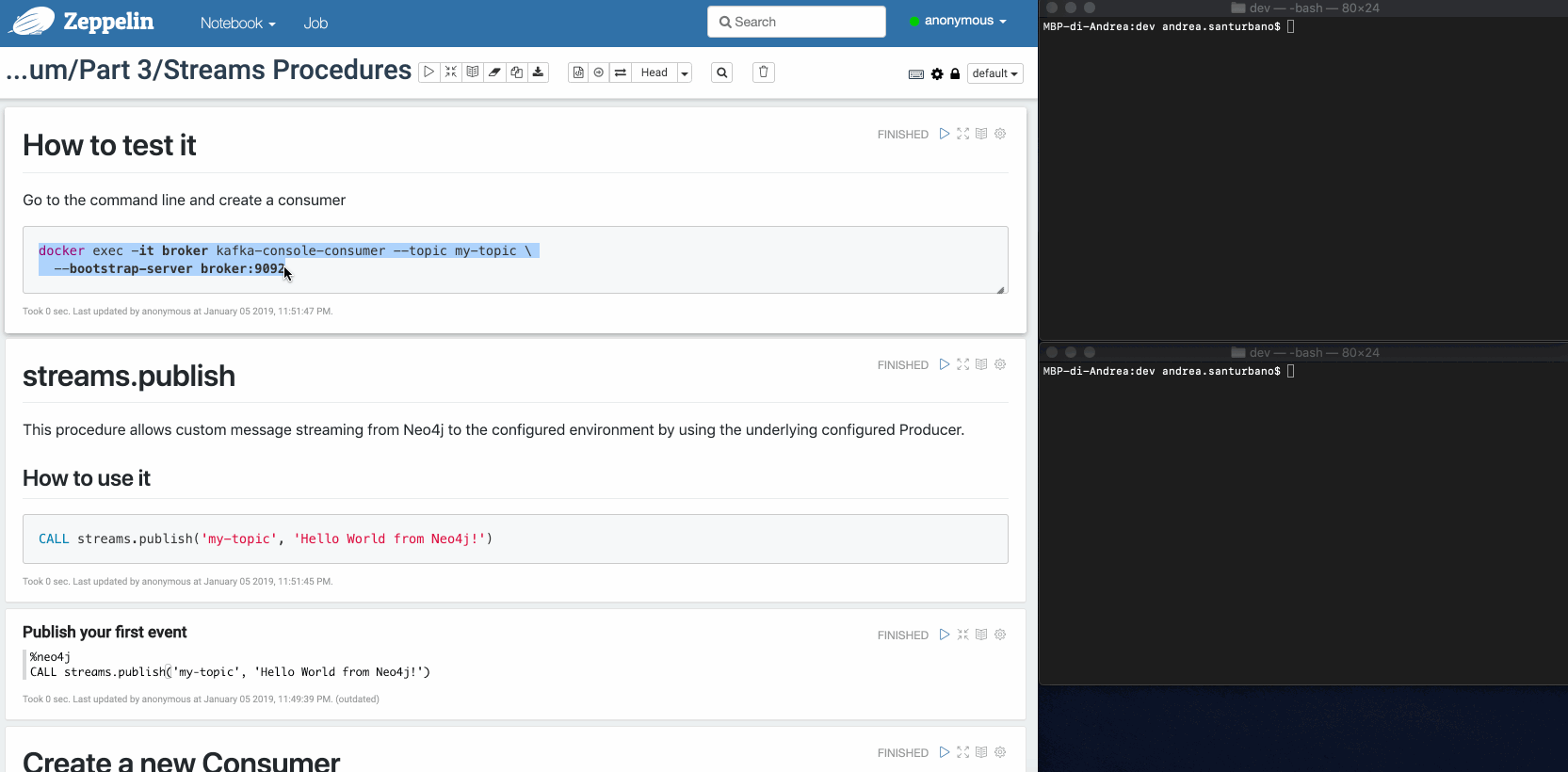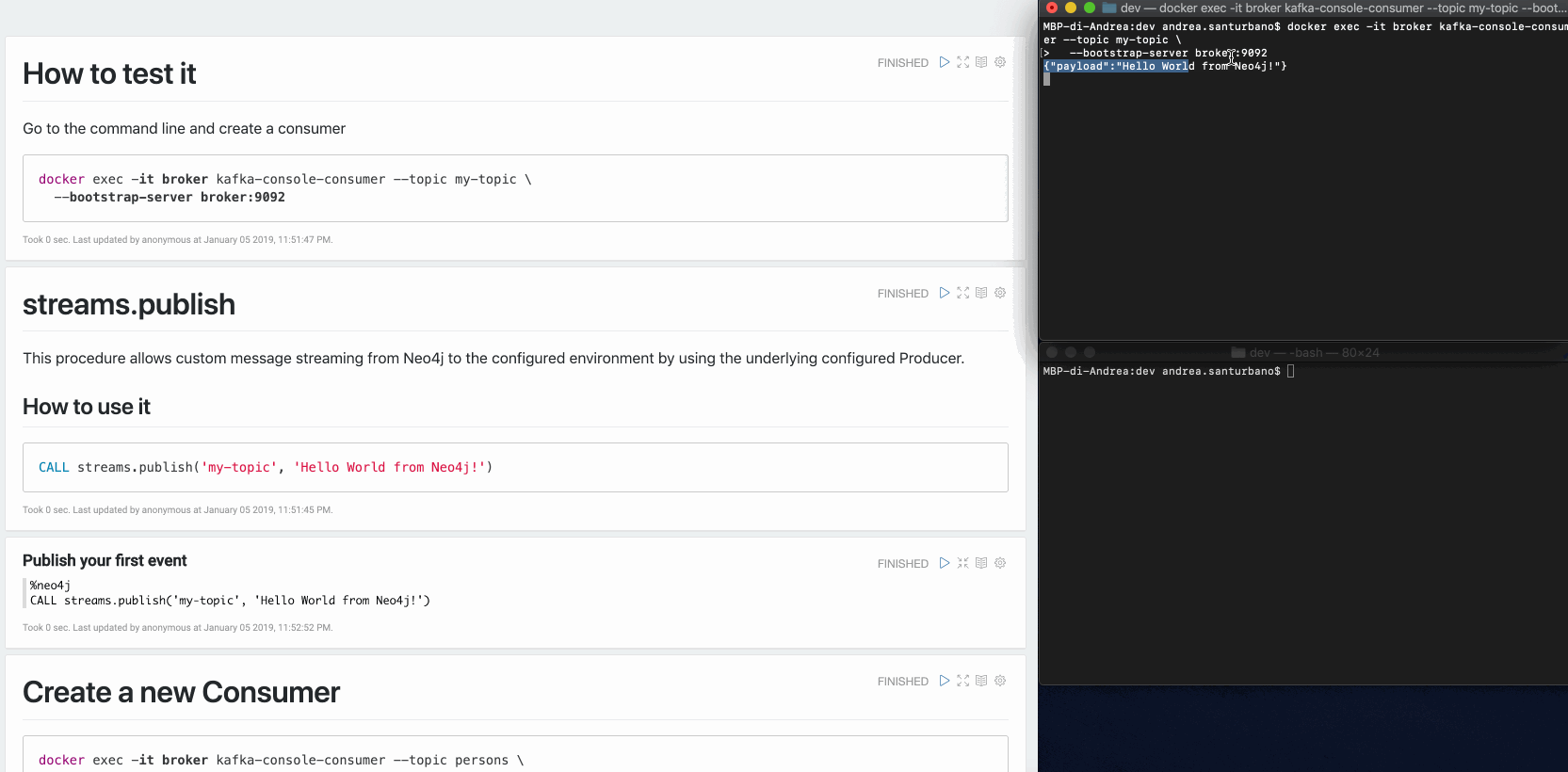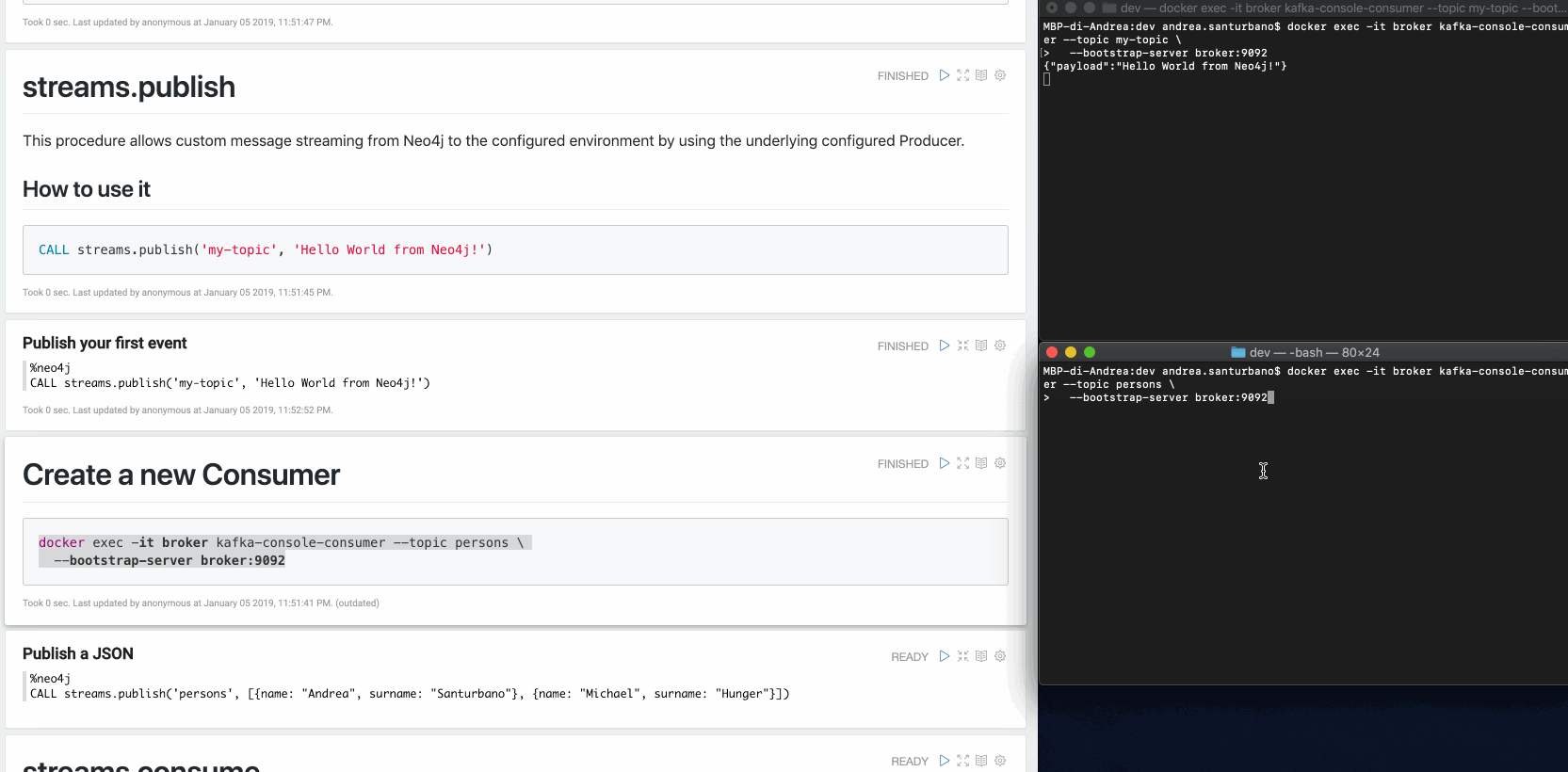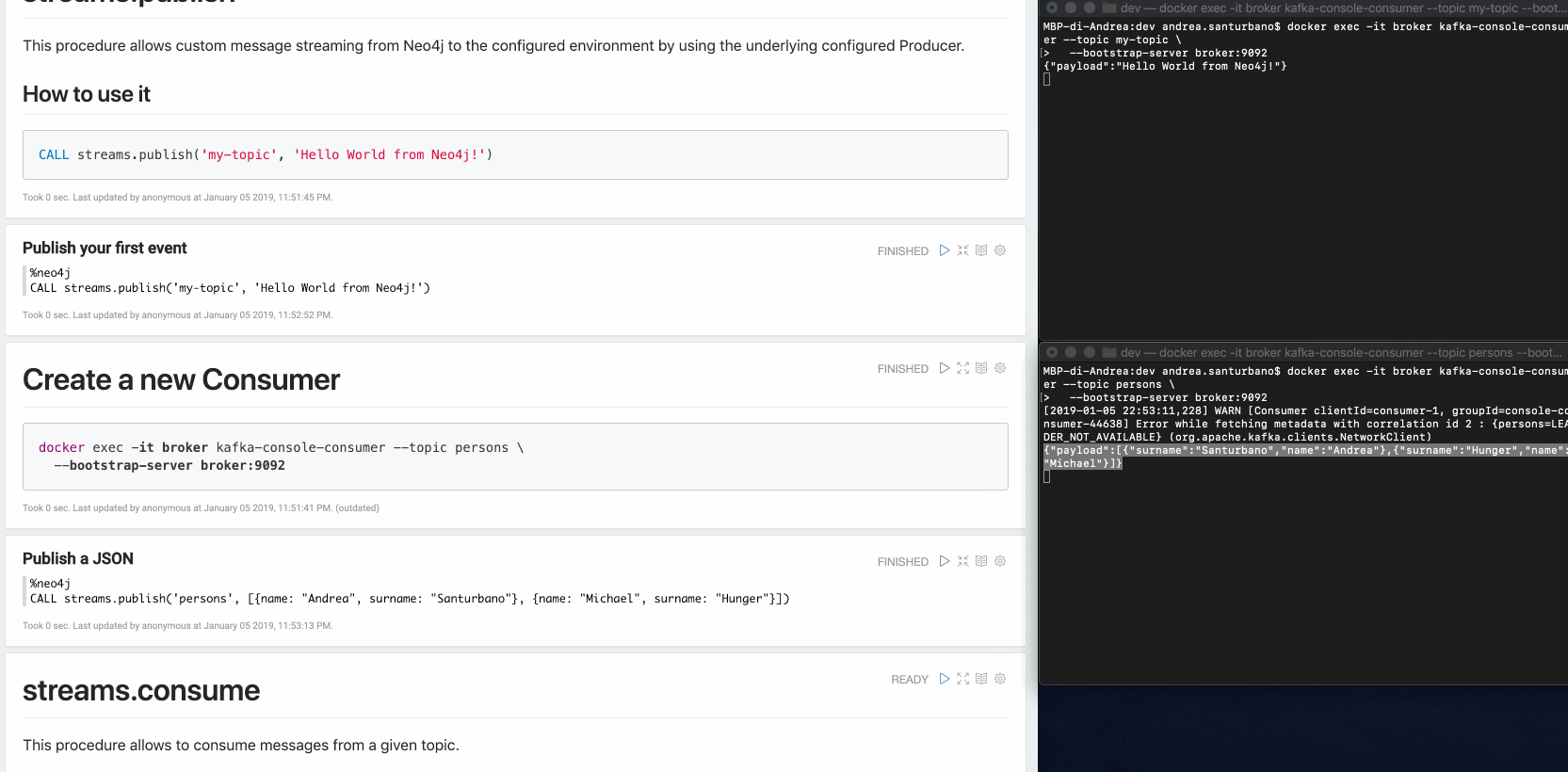
streams.publish
This procedure allows custom message streaming from Neo4j to the configured environment by using the underlying configured Producer.
It takes two variables as input and returns nothing (as it sends its payload asynchronously to the stream):
- topic, type String: where the data will be published
- payload, type Object: what you want to stream.
Example:
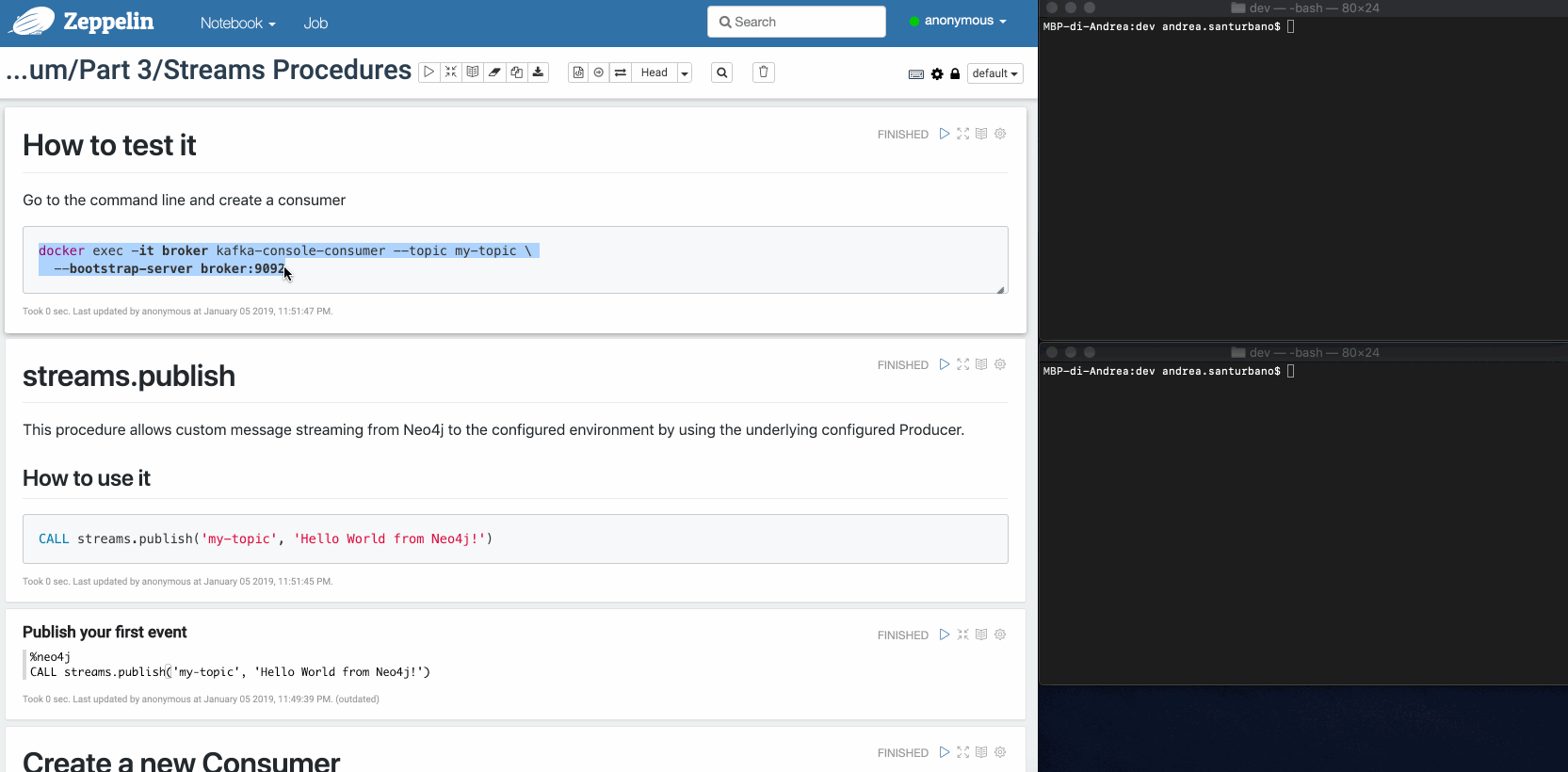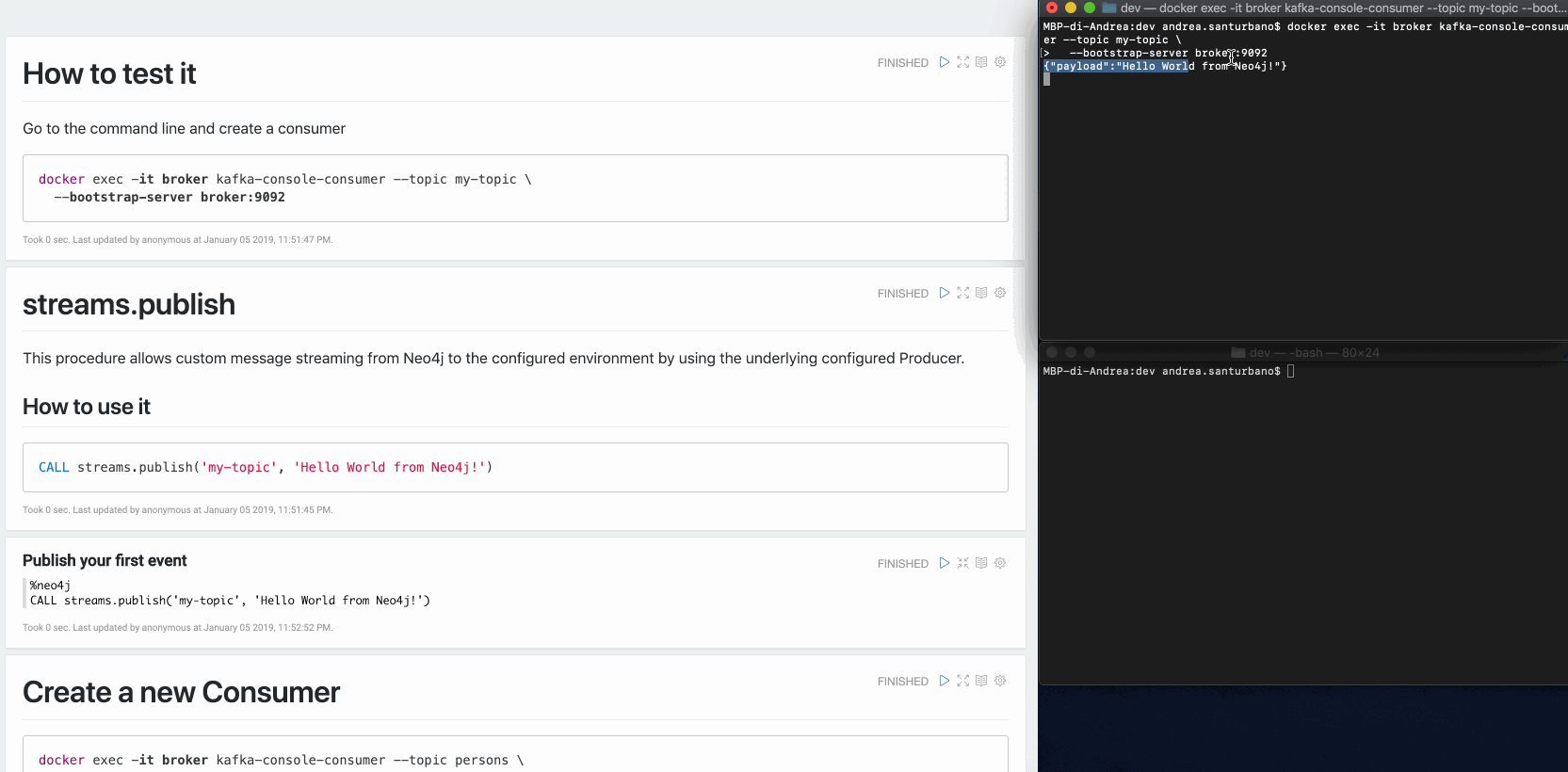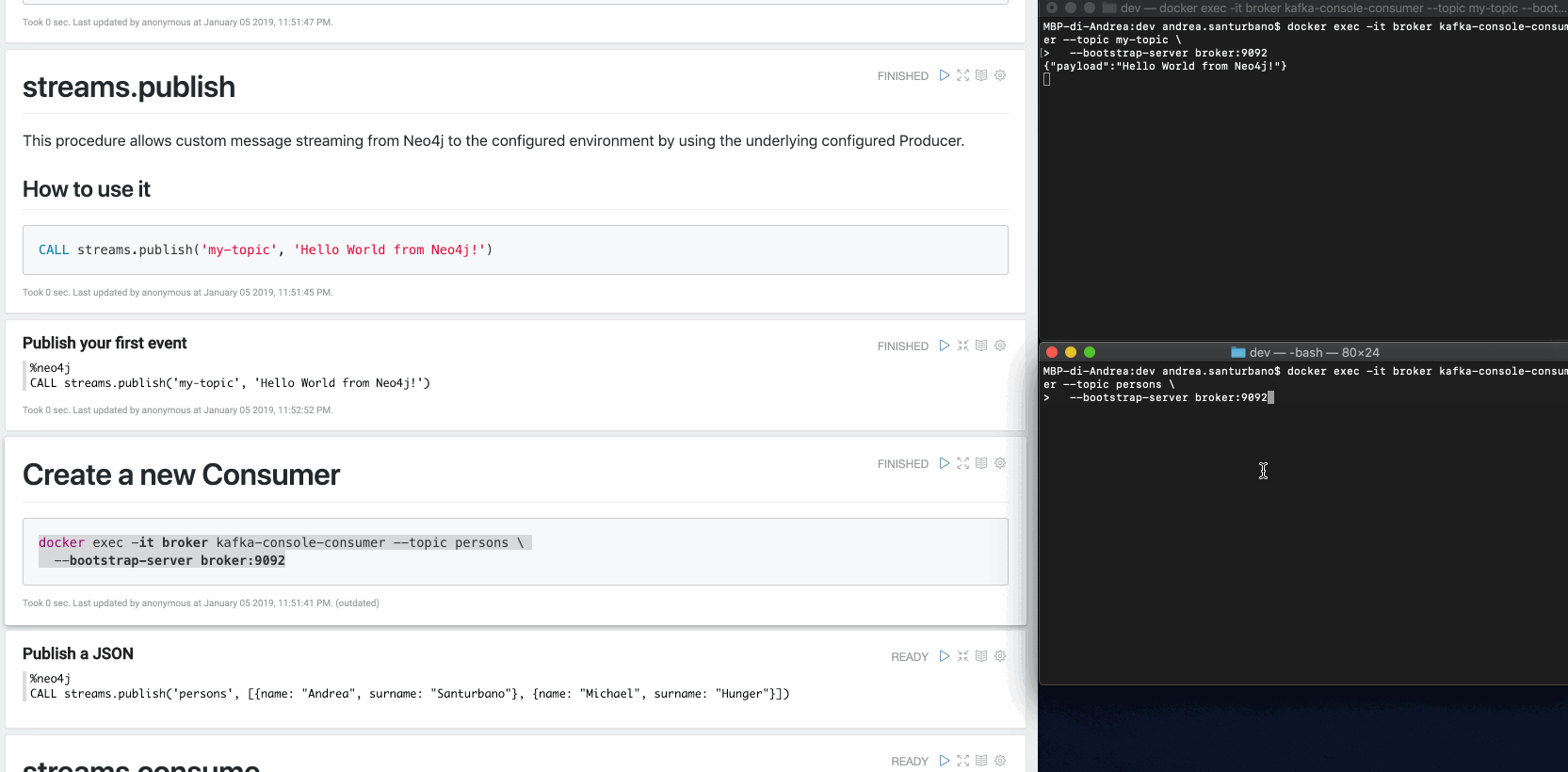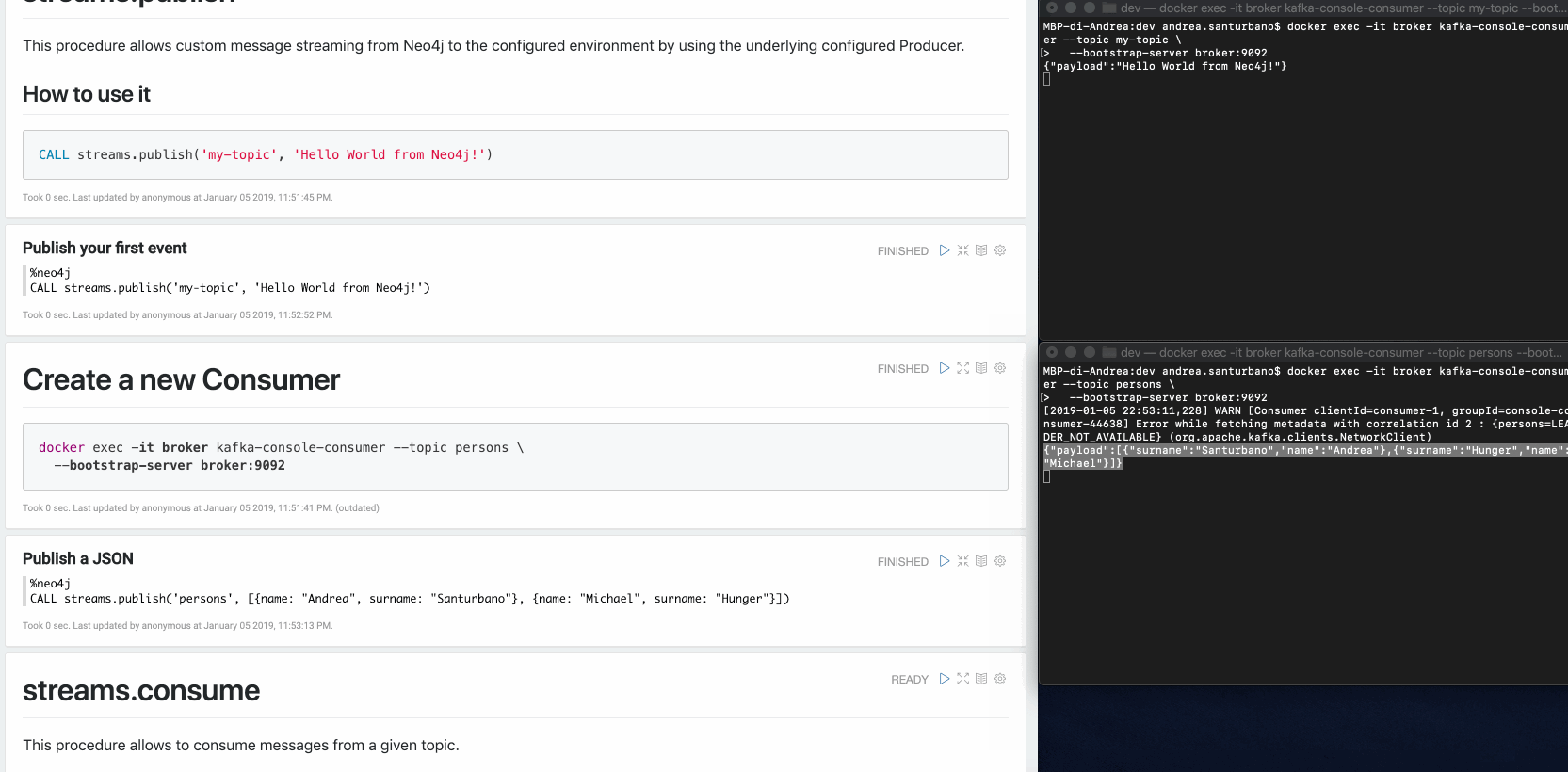
CALL streams.publish('my-topic', 'Hello World from Neo4j!')The message retrieved from the Consumer is the following:
{"payload": "Hello world from Neo4j!"}You can send any kind of data in the payload: nodes, relationships, paths, lists, maps, scalar values and nested versions thereof.
In case of nodes and/or relationships, if the topic is defined in the patterns provided by the Change Data Capture (CDC) configuration, their properties will be filtered according to the configuration.
Following is a simple video that shows the procedure in action:
streams.consume
This procedure allows for consuming messages from a given topic.
It takes two variables as input:
- topic, type String: where you want to consume the data
- config, type Map<String, Object>: the configuration parameters
and returns a list of collected events.
The config params are:
- timeout, type Long: it’s the value passed to Kafka
Consumer#pollmethod (milliseconds). Default 1000. - from, type String: it’s the Kafka configuration parameter
auto.offset.reset
Use:
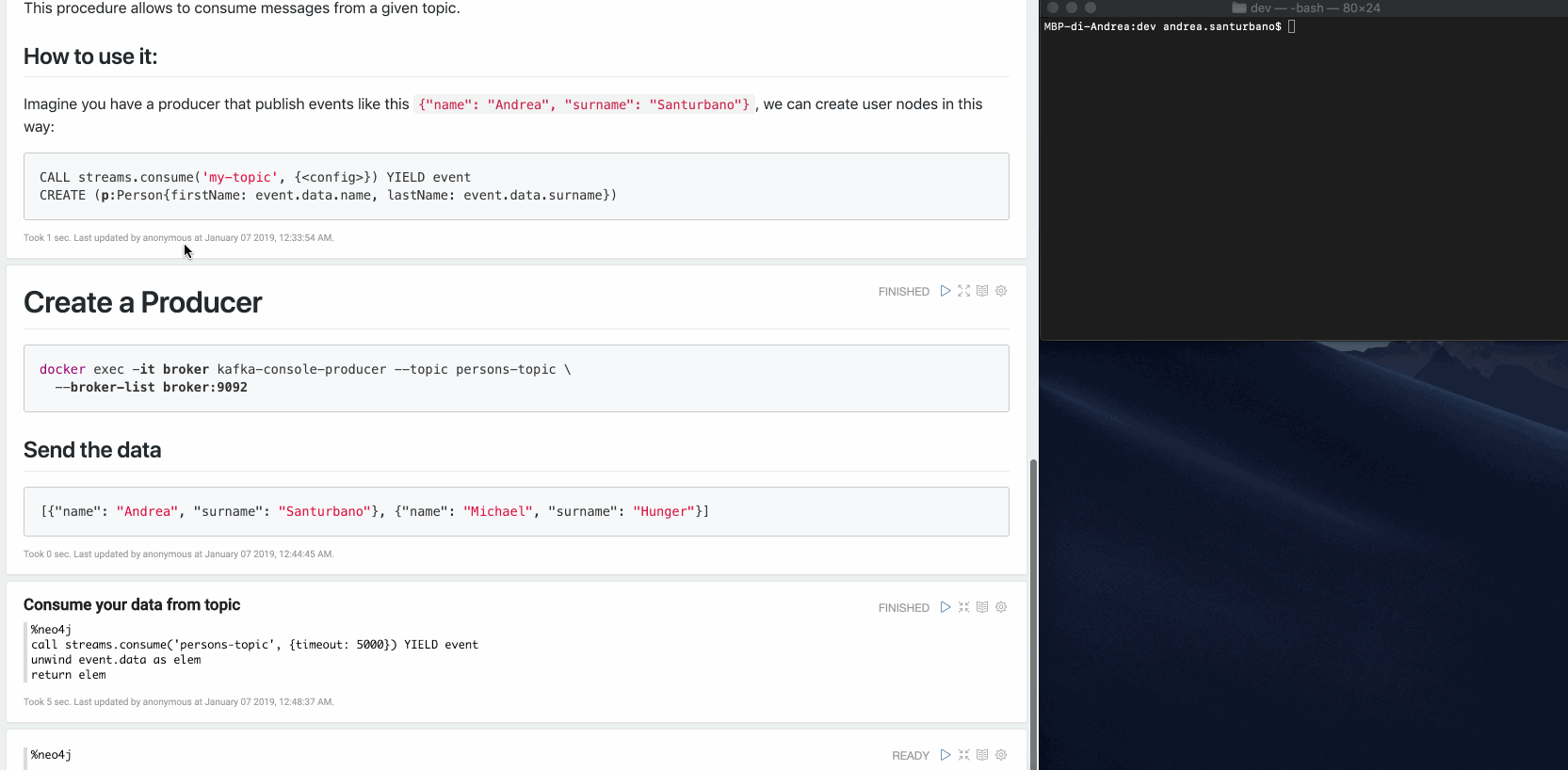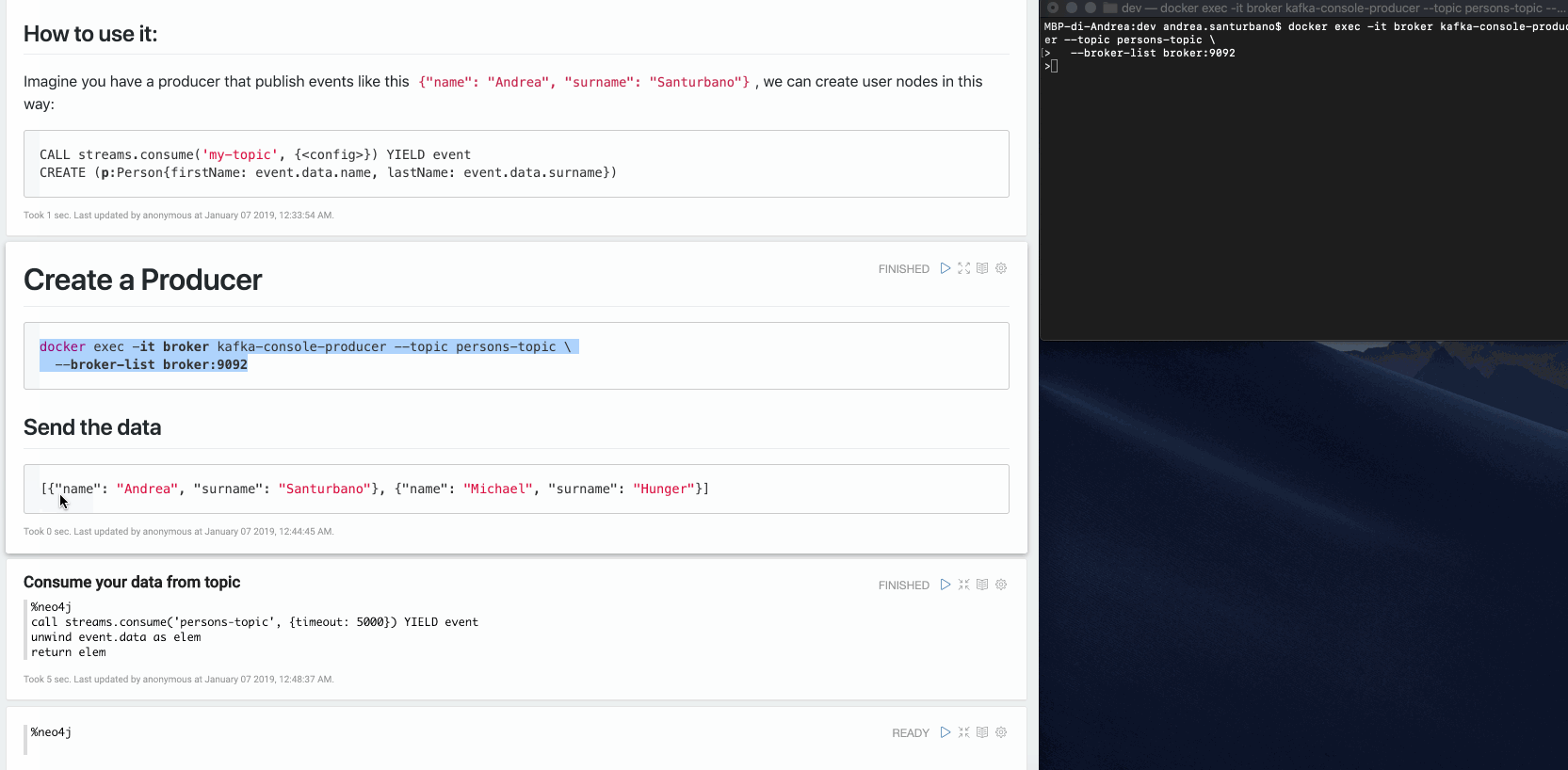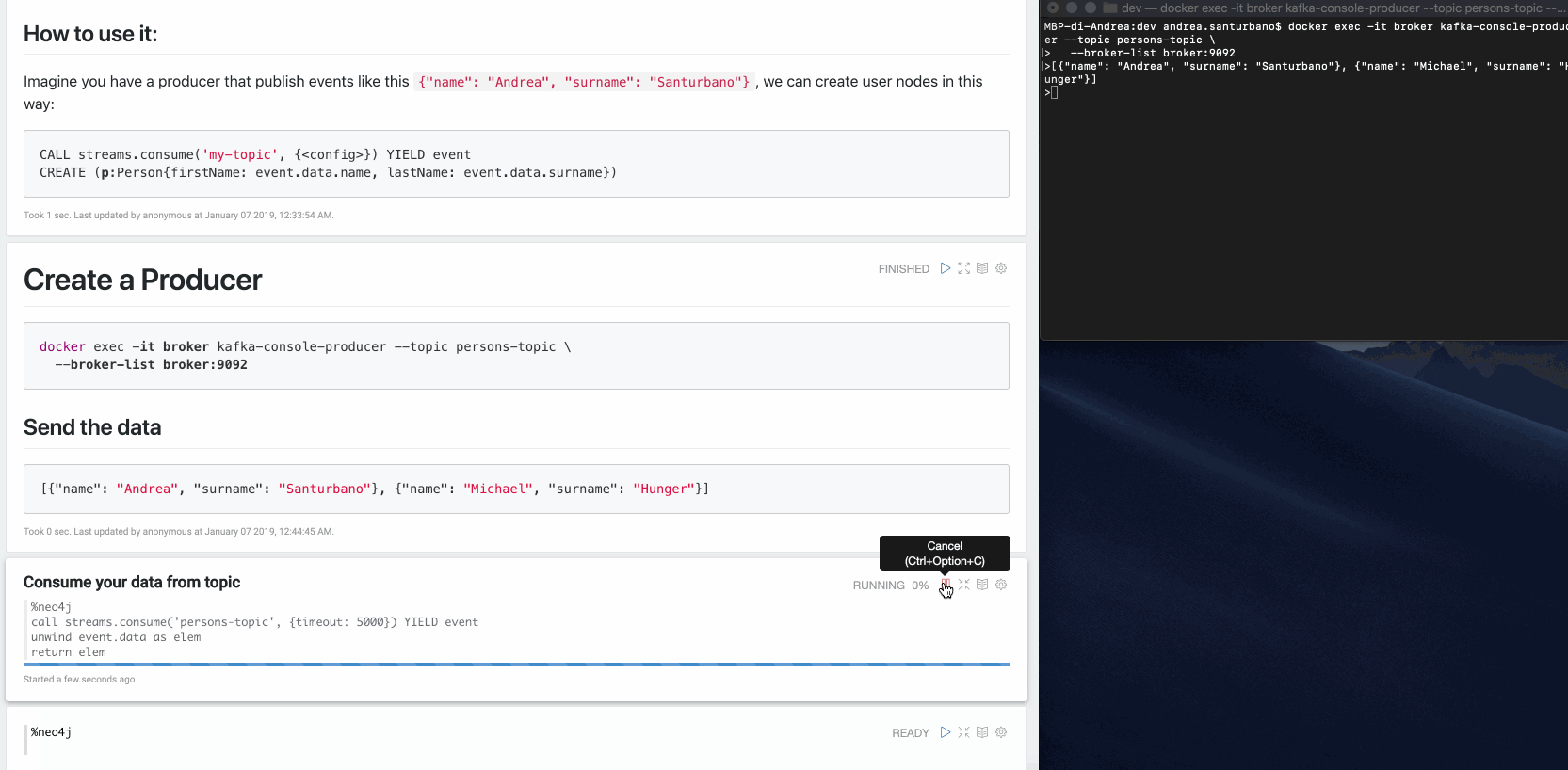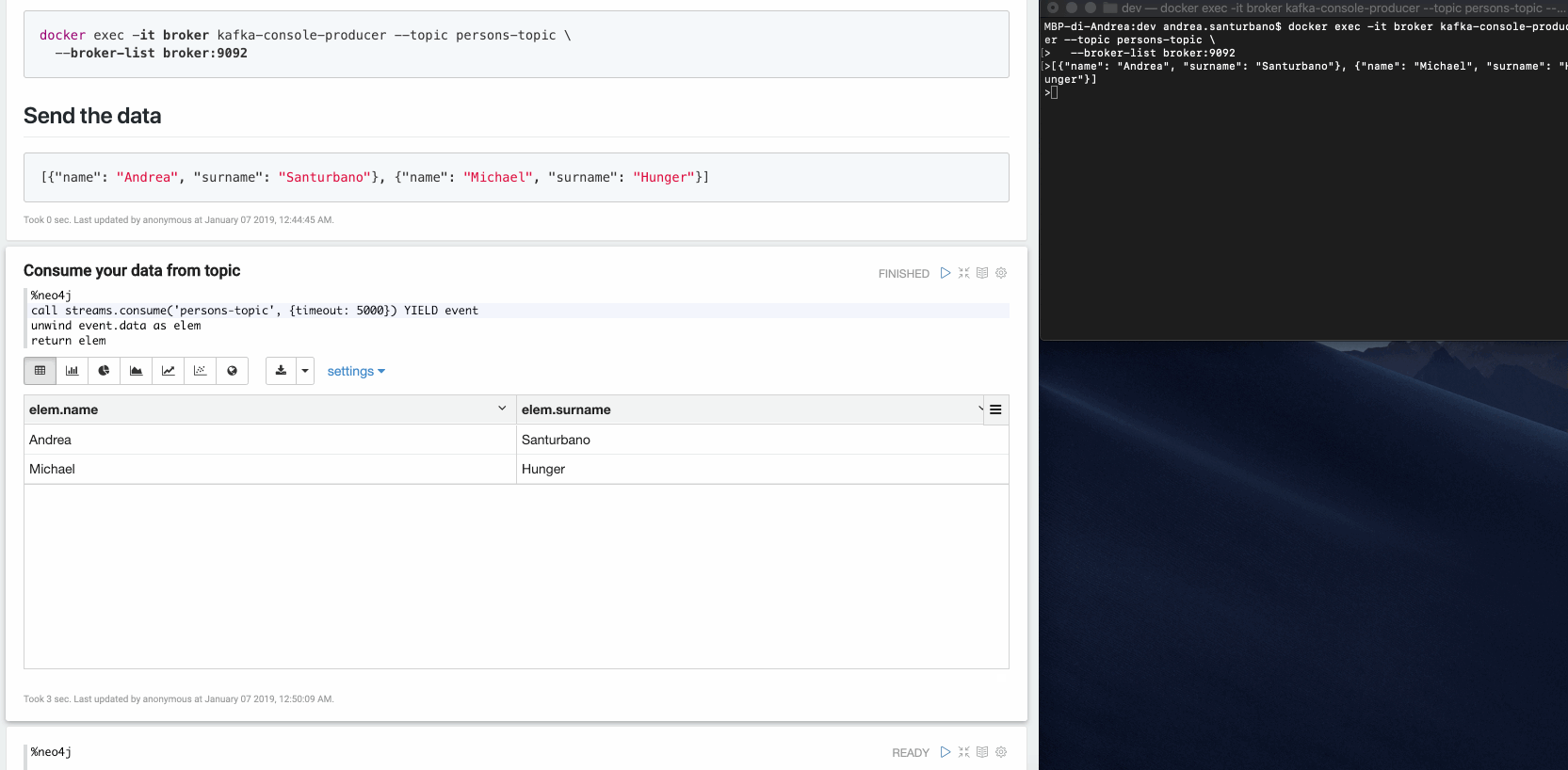
CALL streams.consume('my-topic', {<config>}) YIELD event RETURN eventExample: Imagine you have a producer that publishes events like this:
{"name": "Andrea", "surname": "Santurbano"}We can create user nodes in this way:
CALL streams.consume('my-topic', {<config>}) YIELD eventCREATE (p:Person{firstName: event.data.name, lastName: event.data.surname})Following is a simple video that shows the procedure in action:
So this is the end of the “Leveraging Neo4j Streams” series, I hope you enjoyed it!
If you have already tested the Neo4j-Streams module or tested it via this notebook, please fill out our feedback survey.
If you run into any issues or have thoughts about improving our work, please raise a GitHub issue.