
Teaching a machine to recognize indecent content wasn’t difficult in retrospect, but it sure was tough the first time through.
Here are some lessons learned, and some tips and tricks I uncovered while building an NSFW model.
Though there are lots of ways this could have been implemented, the hope of this post is to provide a friendly narrative so that others can understand what this process can look like.
If you’re new to ML, this will inspire you to train a model. If you’re familiar with it, I’d love to hear how you would have gone about building this model and ask you to share your code.
The Plan:
- Get lots and lots of data
- Label and clean the data
- Use Keras and transfer learning
- Refine your model
Get lots and lots of data
Fortunately, a really cool set of scraping scripts were released for a NSFW dataset. The code is simple already comes with labeled data categories. This means that just accepting this data scraper’s defaults will give us 5 categories pulled from hundreds of subreddits.
The instructions are quite simple, you can simply run the 6 friendly scripts. Pay attention to them as you may decide to change things up.
If you have more subreddits that you’d like to add, you should edit the source URLs before running step 1.
E.g. — If you were to add a new source of neutral examples, you’d add to the subreddit list in nsfw_data_scraper/scripts/source_urls/neutral.txt.Reddit is a great resource of content around the web, since most subreddits are slightly policed by humans to be on target for that subreddit.
Label and clean the data
The data we got from the NSFW data scraper is already labeled! But expect some errors. Especially since Reddit isn’t perfectly curated.
Duplication is also quite common, but fixable without slow human comparison.
The first thing I like to run is duplicate-file-finder which is the fastest exact file match and deleter. It’s powered in Python.
Qarj/duplicate-file-finder
Find duplicate files. Contribute to Qarj/duplicate-file-finder development by creating an account on GitHub.github.com
I can generally get a majority of duplicates knocked out with this command.
python dff.py --path train/path --deleteNow, this doesn’t catch images that are “essentially” the same. For that, I advocate using a Macpaw tool called “Gemini 2”.

While this looks super simple, don’t forget to dig into the automatic duplicates, and select ALL the duplicates until your Gemini screen declares “Nothing Remaining” like so:
It’s safe to say this can take an extreme amount of time if you have a huge dataset. Personally, I ran it on each classification before I ran it on the parent folder in order to keep reasonable runtimes.
Use Keras and transfer learning
I’ve looked at Tensorflow, Pytorch, and raw Python as ways to build a machine learning model from scratch. But I’m not looking to discover something new, I want to effectively do something pre-existing. So I went pragmatic.
I found Keras to be the most practical API for writing a simple model. Even Tensorflow agrees and is currently working to be more Keras-like. Also, with only one graphics card, I’m going to grab a popular pre-existing model + weights, and simply train on top of it with some transfer learning.
After a little research, I chose Inception v3 weighted with imagenet. To me, that's like going to the pre-existing ML store and buying the Aston Martin. We’ll just shave off the top layer so we can use that model to our needs.
conv_base = InceptionV3(
weights='imagenet',
include_top=False,
input_shape=(height, width, num_channels)
)
With the model in place, I added 3 more layers. A 256 hidden neuron layer, followed by a hidden 128 neuron layer, followed by a final 5 neuron layer. The latter being the ultimate classification into the five final classes moderated by softmax.
# Add 256
x = Dense(256, activation='relu', kernel_initializer=initializers.he_normal(seed=None), kernel_regularizer=regularizers.l2(.0005))(x)
x = Dropout(0.5)(x)
# Add 128
x = Dense(128,activation='relu', kernel_initializer=initializers.he_normal(seed=None))(x)
x = Dropout(0.25)(x)
# Add 5
predictions = Dense(5, kernel_initializer="glorot_uniform", activation='softmax')(x)Visually this code turns into this:
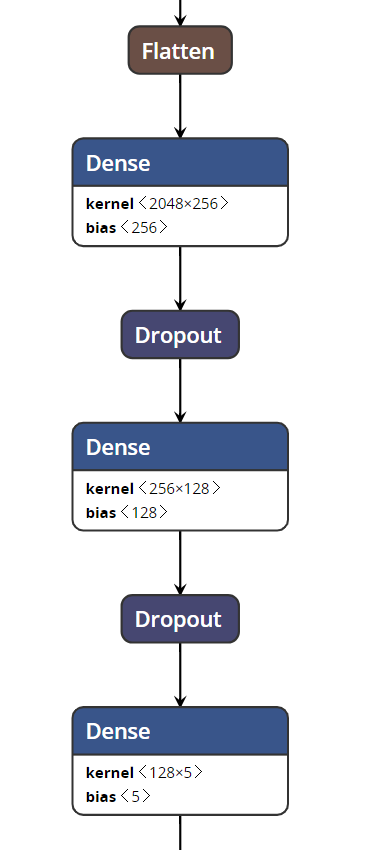
Some of the above might seem odd. After all, it’s not everyday you say “glorot_uniform”. But strange words aside, my new hidden layers are being regularized to prevent overfitting.
I’m using dropout, which will randomly remove neural pathways so no one feature dominates the model.

Additionally, I’ve added L2 regularization to the first layer as well.
Now that the model is done, I augmented my dataset with some generated agitation. I rotated, shifted, cropped, sheered, zoomed, flipped, and channel shifted my training images. This helps with assuring the images are trained through common noise.
All the above systems are meant to prevent overfitting the model on the training data. Even if it is a ton of data, I want to keep the model as generalizable to new data as possible.

After running this for a long time, I got around 87% accuracy on the model! That’s a pretty good version one! Let’s make it great.
Refine your model
Basic fine-tuning
Once the new layers are trained up, you can unlock some deeper layers in your Inception model for retraining. The following code unlocks everything after as of the layer conv2d_56.
set_trainable = False
for layer in conv_base.layers:
if layer.name == 'conv2d_56':
set_trainable = True
if set_trainable:
layer.trainable = True
else:
layer.trainable = FalseI ran the model for a long time with these newly unlocked layers, and once I added exponential decay (via a scheduled learning rate), the model converged on a 91% accuracy on my test data!
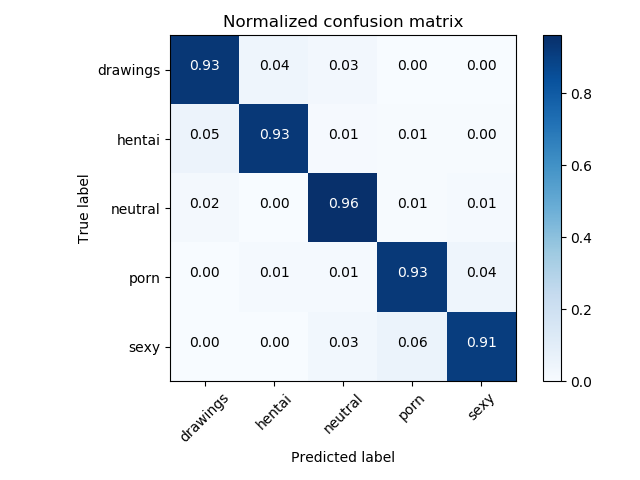
With 300,000 images, finding mistakes in the training data was impossible. But with a model with only 9% error, I could break down the errors by category, and then I could look at only around 5,400 images! Essentially, I could use the model to help me find misclassifications and clean the dataset!
Technically, this would find false negatives only. Doing nothing for bias on the false positives, but with something that detects NSFW content, I imagine recall is more important than precision.
The most important part of refining
Even if you have a lot of test data, it’s usually pulled from the same well. The best test is to make it easy for others to use and check your model. This works best in open source and simple demos. I released http://nsfwjs.com which helped the community identify bias, and the community did just that!

The community got two interesting indicators of bias fairly quickly. The fun one was that Jeffrey Goldblum kept getting miscategorized, and the not-so-fun one was that the model was overly sensitive to females.
Once you start getting into hundreds of thousands of images, it’s hard for one person (like moi) to identify where an issue might be. Even if I looked through a thousand images in detail for bias, I wouldn’t have even scratched the surface of the dataset as a whole.
That’s why it’s important to speak up. Misclassifying Jeff Goldblum is an entertaining data point, but identifying, documenting, and filing a ticket with examples does something powerful and good. I was able to get to work on fixing the bias.
With new images, improved training, and better validation I was able to retrain the model over a few weeks and attain a much better outcome. The resulting model was far more accurate in the wild. Well, unless you laughed as hard as I did about the Jeff Goldblum issue.
If I could manufacture one flaw… I’d keep Jeff. But alas, we have hit 93% accuracy!
In Summary
It might have taken a lot of time, but it wasn’t hard, and it was fun to build a model. I suggest you grab the source code and try it for yourself! I’ll probably even attempt to retrain the model with other frameworks for comparison.
Show me what you’ve got. Contribute or ? Star/watch the repo if you’d like to see progress: https://github.com/GantMan/nsfw_model


Gant Laborde is Chief Technology Strategist at Infinite Red, a published author, adjunct professor, worldwide public speaker, and mad scientist in training. Clap/follow/tweet or visit him at a conference.
Have a minute? Check out a few more:
Avoid Nightmares — NSFW JS
Client-side indecent content checking for the soulshift.infinite.red5 Things that Suck about Remote Work
The Pitfalls of Remote Work + Proposed Solutionsshift.infinite.red