Introduction
From my experience as a time traveller, I can confidently say that autonomous driving is/was/will be all the craze. Mathematically, the hype around computer vision grows exponentially as a function of the index of plank time iterations. Just kidding.
Anyways, in this post, we’ll dive into some of the more recent developments in computer vision with deep learning, and eventually build up to a model called “Mask R-CNN”. This post should be fairly intuitive, but I expect you to know some of the more basic models for computer vision. If you think you’re ready, let’s begin.
Object detection vs. Semantic segmentation vs. Instance segmentation
In this post, I’m assuming that you are comfortable with basic deep learning tasks and models specific to computer vision, such as convolutional neural networks (CNN), image classification etc. If these terms sound like jargon to you, go ahead and read this post.
Ok, now let’s move on to the fun stuff. Besides the traditional dog vs. cat classifier that most of us would have built on our deep learning journey, there is a whole lot more we can do with the very same idea of a neural network.
For example, instead of just telling us what’s in an image, we can train our CNN to tell us which part of the image convinced it to make that decision. To see why this is useful, be sure to check out this Ted talk. This can be done by asking the CNN to draw a box around the object, like in the below image:
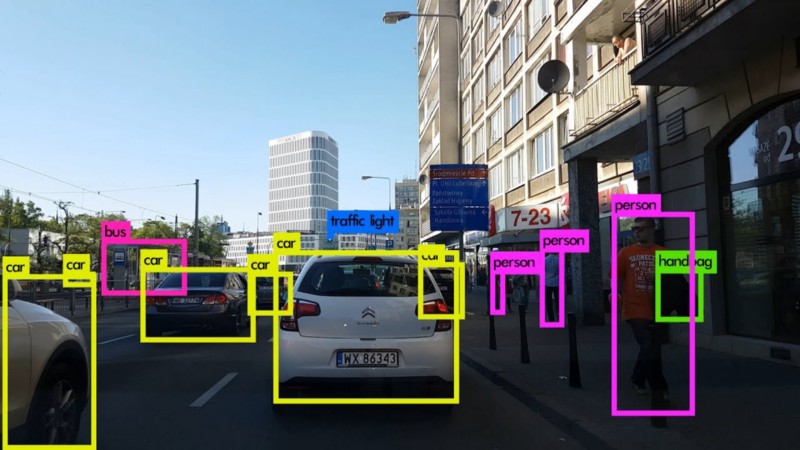
In deep learning language, this task is called object detection, and it is really quite easy to implement. First, when preparing our data, we need to use a tool to draw bounding boxes around images. This is quite easy using free online tools. Then, we change the final/output layer of the CNN to a softmax layer that has 4 + k outputs — the x-coordinate of the bounding box, the y-coordinate of the bounding box, the height of the bounding box, the width of the bounding box, and class probability scores for k classes.
The first thing you might ask is why we choose weird things to learn like the x,y coordinates and the height, width. Can’t we just learn the (x,y) coordinates of each corner of the box? Well, we can — however, if we learn 4 pairs of variables, we have to learn 8 in total to represent the box. However, if we use this technique, we only need to use 4.
Another interesting task we can solve is semantic segmentation. Again, this is just a fancy word for what is essentially colouring an image like in a children’s colouring book.

Similar to the case of object detection, a free tool could be used to essentially colour an image manually, which is used as the ground truth example for preparing a dataset. Here, our neural network is trained to map each pixel in the input image to a particular class. Crudely, can be done by using something called a fully convolutional network (FCN). This network is just a series of convolutional layers .
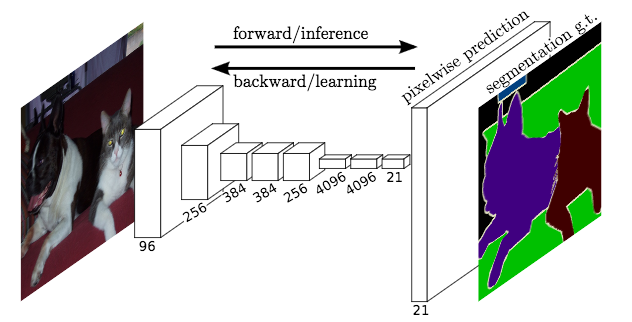
So, the FCN would learn (through the mystic dark art of deep learning) the mapping from an input image to a “coloured in” version of it, that highlights the different classes in an image.
An important thing to note is that semantic segmentation does not highlight individual instances of a class differently. For example, if there were 3 cows in an image, the model would highlight the area they occupy, but it will not be able to distinguish one cow from another. If we want to add this functionality, we need to extend the task and introduce another term to complicate the already enormously large vocabulary of deep learning — instance segmentation.
Ok, it wasn’t really all that bad, was it? The term is pretty much self-explanatory. Our goal is to segment or separate each “instance” of a class in an image. This should help you visualize what we are trying to achieve:

The actual model we use to solve this problem is actually much simpler than you might think. Instance segmentation can essentially be solved in 2 steps:
- Perform a version of object detection to draw bounding boxes around each instance of a class
- Perform semantic segmentation on each of the bounding boxes
This amazing simple model actually performs extremely well. It works, because if we assume step 1 to have a high accuracy, then semantic segmentation in step 2 is provided a set of images which are guaranteed to have only 1 instance of the main class. The job of the model in step 2 is to just take in an image with exactly 1 main class, and predict which pixels correspond to the main class (cat/dog/human etc.), and which pixels correspond to the background of an image.
Another interesting fact is that if we are able to solve the multi bounding box problem and semantic segmentation problem independently, we have also essentially solved the task of instance segmentation! The good news is that very powerful models have been built to solve both of these problems, and putting the 2 together is a relatively trivial task.
This particular model has a name — Mask R-CNN (short for “regional convolutional neural network”), and it was built by the Facebook AI research team (FAIR) in April 2017.
The working principle of Mask R-CNN is again quite simple. All they (the researchers) did was stitch 2 previously existing state of the art models together and played around with the linear algebra (deep learning research in a nutshell). The model can be roughly divided into 2 parts — a region proposal network (RPN) and binary mask classifier.
Step one is to get a set of bounding boxes that could possibly contain an object of relevance. The fancy word of the day here is RoI Align. The RoI Align network works on principles of object detection (discussed above, did you forget already!), but it outputs multiple possible bounding boxes rather than a single definite one. These boxes are refined using another regression model, which we will not discuss here. More details on the RoI Align network can be found here.
The second stage is to actually do the colouring. Au contraire to what one might think, this step is also quite easy! All you need to do is apply the existing state of the art model for semantic segmentation to each bounding box. The cool part is that since we are guaranteed to have at most 1 class in each box, we just to train our semantic segmentation model like a binary classifier, meaning we only need to learn the mapping from input pixels to a 1/0. 1 would represent the presence of an object, and 0 would be the background. Then, for added flair, we could color each of the pixels that map to 1 to get funky looking results that look like this:

Conclusion
The applications of this technology are far-reaching. Some of the more lucrative use-cases include motion capture, autonomous driving and surveillance systems. But we’ll leave all the applications of this technology in the minds of the reader.
For the most part, instance segmentation is now quite achievable, and it’s time to start thinking about innovative ways of using this idea of doing computer vision algorithms at a pixel by pixel level. A good example would be a cool new algorithm called DensePose. For some unknown reason, this model is not getting a lot of press. But the potential is greater than that of the gravitation of a black hole!
Put simply, think of DensePose as kinect on the cheap. It can essentially do whatever an advanced motion capture system can do for a fraction of a fraction of a cost. In theory, you could run this model on a $10 device like as raspberry pi!
From a theoretical perspective (aka the cooler one), this technology could be extended to other types of neural nets (other than CNNs and FCNs). The main idea here is that of taking the most elementary portion of some data (a pixel in this case), and deciding how it contributes to the overall structure.
Hypothetically, we could classify each individual sample from a signal and decide how it contributes to a sequence of music. If we’re even more ambitious, we could identify which parts of a sequence of music is most appealing, and combine it with appealing parts from other songs, resulting in a novel way to fuse our favorite songs together!
On a more serious note, we could use the same technique for more important data. For example, we could train a Mask R-CNN model to highlight which exact areas of an MRI scan correlate to certain behavioral/psychological patterns, or which sub-sequences of DNA correspond to some particular traits, potentially resulting in breakthroughs in medical AI.
The Mask R-CNN model, at its core, is about breaking data into its most fundamental building blocks. As humans, we have inherent biases in the way we look at the world. AI, on the other hand, has the potential to look at the world in ways we humans couldn’t even comprehend, and as it was once said by a man who mastered the art of looking for the most fundamental truths: