
by Michael Hunger
How you can use a GraphQL API for database administration

A recent discussion at graphql-europe made me realize that GraphQL would make for an amazing API for database administration.
You know that plethora of functions and options to control details from security, indexing, metadata, clustering, and other operations?
I used the trip home on the train to build a GraphQL admin endpoint for Neo4j, exposing all available procedures either as queries or mutations. Using Kotlin, this was fortunately a matter of only a few lines (200) of code. And it worked surprisingly well.
If you know of any other database that exposes its admin-API via GraphQL, please let me know in the comments — I’d love to have a look.
And if you get inspired to base some of your work on this idea, I’d be honored, even more so with attribution :)
TL;DR
You can get your Neo4j Admin API served at /graphql/admin by installing the lastest version of the neo4j-graphqlextension. In Neo4j Desktop just click "Install GraphQL" in the Plugins section of your database (version 3.4.0.1). You might need to configure a basic auth header for your database user’s credentials. Then you’re ready to query your new and shiny Admin API via GraphiQL or GraphQL Playground.
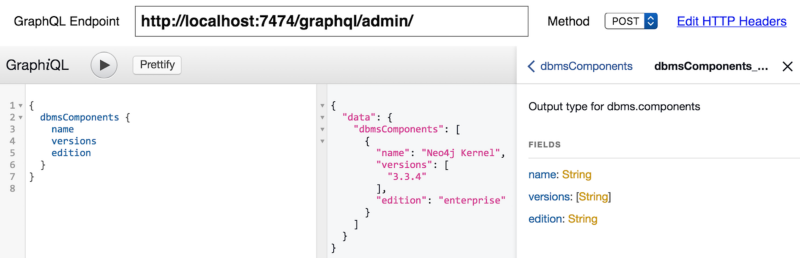
The endpoint is not limited to built-in procedures. External libraries like APOC, graph-algorithms, or neo4j-spatial are automatically exposed.
Benefits
In my book, the biggest benefit is the self documenting nature of GraphQL APIs based on the strict schema provided.
The strong typing, documentation, and defaults for both input and output types increase the clarity and reduce the number of trial-and-error attempts. The custom selection of output fields and optional deeper traversal of result structures allows for quick customizations of what you want to retrieve.
With the clear separation into read queries and write mutations, it is easy to reason about the impact of a call.
And of course the amazing auto-complete with inline help and the automatically available documentation in GraphiQL and GraphQL-Playground make interacting with such an API a joy. ?
Parameterizing all inputs and limiting result sizes is just icing on the ?.
Another advantage is that you can combine multiple queries into a single call. All relevant information for a full screen is retrieved in a single request.
Of course you can use all the available GraphQL tools like middleware or libraries for quickly building front-end applications (apollo-tools, React, semantic-ui, victory, etc.). That allows you to integrate these APIs quickly into your monitoring/administration scripts or dashboards.
Implementation Details
Like the regular GraphQL endpoint in neo4j-graphql, this is a server extension serving GET, POST, and OPTIONS endpoints. They take in queries, variables and operation names to execute within a single transaction. After execution, the results or errors are returned as JSON to the client.
The necessary graphql-schema is built from the available user-defined-procedures deployed in Neo4j.
You have to explicitely allow procedures to be exposed via the config setting graphql.admin.procedures.(read/write) with either Neo4j procedure syntax or admin-endpoint field names. For example, you could set it to:
graphql.admin.procedures.read=db.*,dbms.components,dbms.queryJ*graphql.admin.procedures.write=db.create*,dbIndexExplicitFor*User Defined Procedures
In 2016, Neo4j 3.0 got a neat new extension point. You could provide annotated Java methods as user defined procedures, which then were callable either stand-alone or as part of your database queries. As our (React-based) Neo4j-Browser moved from HTTP to a binary transport, the original management REST-APIs were augmented with procedures providing the same functionality.
Each procedure can take parameters and returns a stream of data with individually named columns, similar to regular query results. Both inputs and outputs can use data types from the Cypher type system.
call dbms.listConfig('dbms.connector.http') yield name, value, description;╒══════════════════════════════╤═══════╤════════════════════════╕│"name" │"value"│"description" │╞══════════════════════════════╪═══════╪════════════════════════╡│"dbms.connector.http.enabled" │"true" │"Enable this connector."│├──────────────────────────────┼───────┼────────────────────────┤│"dbms.connector.https.enabled"│"true" │"Enable this connector."│└──────────────────────────────┴───────┴────────────────────────┘Ever since, a large amount of functionality has been moved to procedures and functions, giving us a broad selection of things to expose via GraphQL.
To construct the schema, I iterated over the available procedures, creating one field for each procedure.
I took the named procedure parameters as input arguments and used custom output types (per procedure) holding the returned columns. Input parameters with default values could be nullable, the others are defined as non-null. Procedure descriptions turned into field descriptions, and the deprecation information was also transferred.
I mapped basic scalar types and lists directly to GraphQL types.
Only for the Map (dict/object) type did I have to map to a List<Attribute> where each attribute is
type Attribute { name: String! value: String type: String! = "String"}which worked suprisingly well both for inputs and outputs.
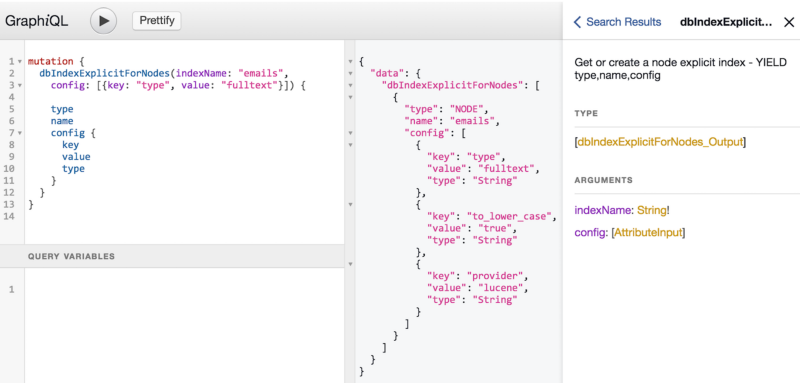
Similarly, I created custom types for Node, Relationship and Path.
For these four custom types, I added the appropriate (de-)serialization code. All other unknown types were rendered to strings.
The resolver for each field just executes the wrapped procedure with the input arguments from the environment. The results are then mapped to the output type fields (optionally transformed) and returned to the endpoint.
Based on their metadata, I combined the fields into object types for Queries and Mutations, respectively.
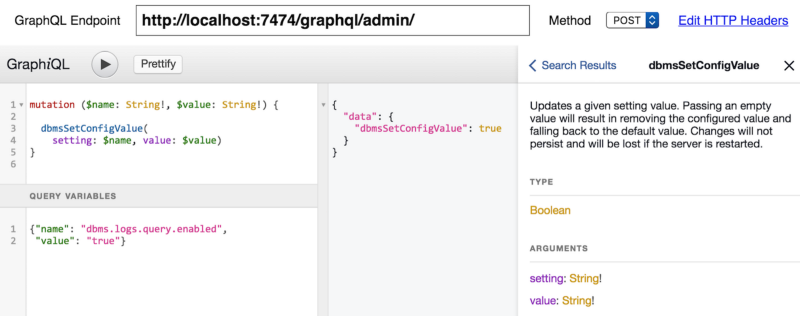
And that was basically it.
I was surprised myself when I fired up GraphiQL after deploying the extension that I was able to intuitively call any of the queries and mutations without hiccups.
Challenges
My biggest challenge is the lack of namespaces in GraphQL. While you can substructure queries nicely with nested types, the same is not available for mutations.
To keep the API naming consistent across both, I decided not to substructure queries and like mutations, and instead joined the capitalized parts of the namespace and procedure name together.
So db.labels turns into dbLabels .
Another slight challenge was the missing information about read vs. write operations in the DBMS and SCHEMA scopes of Neo4j procedures. So I had to use a whitelist to determine "read-only" ones, which of course is not sufficient.
Notables
Something that other API technologies don’t have built in, and which is really cool, is the ability to choose and pick any number of queries or mutations you want to run in a single request.
If necessary, you can even alias multiple invocations of the same query with different parameters (think statistics per database).
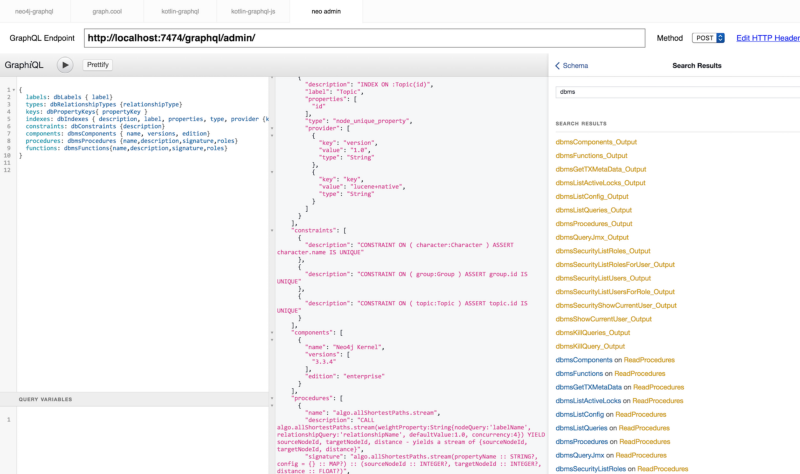
And you can even run graph-algorithms or cypher statements as part of this API, which is kinda cool.
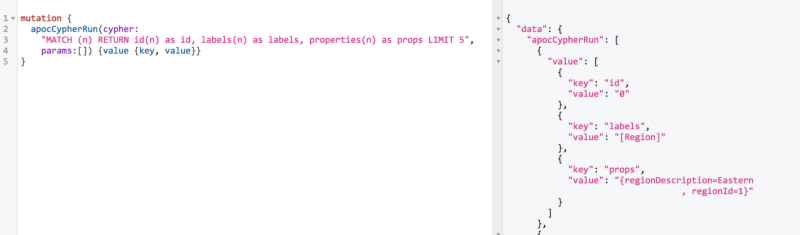
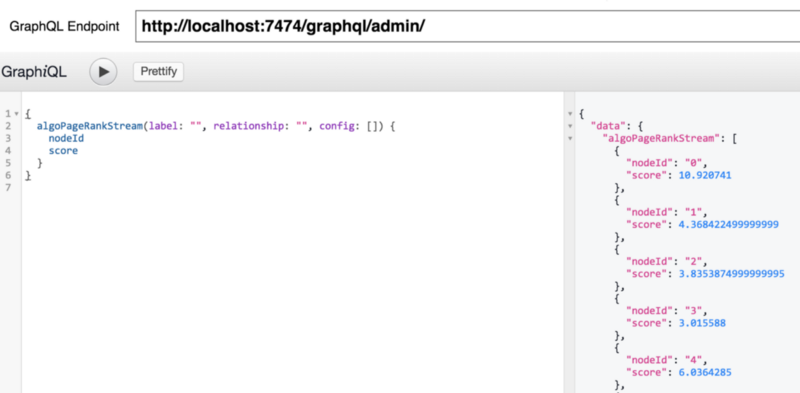
Next Steps
Currently, I only directly expose the procedures parameters and results to the users. Going forward, it would be nice to derive higher level types that offer their own (dynamic) query fields, like
- a Label type that also can return counts
- a Server type that can provide its cluster role or other local information
- adding more dynamic fields with parameters on a Node or Relationship type for custom traversals
I would love ? a bunch of monitoring and management mobile-, web-apps and command-line-clients to be built on top of this management API.
I’m excited to see where we could improve the usability and what feedback and requests we get. Of course the first target would a graph-app for Neo4j Desktop. So if you’re interested in any of this, please reach out and let’s chat.
Happy hacking! — Michael
If you run into any problems, please add a comment or raise a GitHub issue.